IAT被壳修改如何修复IAT
很多比较鸡贼的壳都会修改程序的IAT,这里说的修改不是指加壳以后的修改(加壳以后几乎所有的壳都会重建程序的IAT),而是指程序到达真正的OEP以后,发现IAT表中很多函数指到了别的地方,导致ImportRec无法修复.
原理
加壳程序要保证原程序能够正常运行,必须在程序到达真正的OEP之前将程序的IAT恢复出来,这里说的恢复有下面两种情况:
- 1.原封不动的恢复
- 2.修改原IAT表中的项,让他指向一个新的函数,这个函数实现了原导入函数相似的功能.
第一种就不多说了,直接上ImportREC搞定,至于第二种,可以使用如下方法:
我们知道,程序在加载IAT时,需要从相应的DLL中读出指定的函数,我们就可以从这里入手,因为上面两种情况都会执行这个步骤.当IAT加载代码从DLL中读出原函数以后,是不是要经过相应的处理,变化,然后把得到的结果放到IAT对应的项中?我们的目的就是阻止这些修改!
过程
不同的壳情况当然也不一样,我们这里使用一个加壳的记事本程序,PEID没查到壳,不要紧,方法都是通用的
这种方法需要先脱壳,脱壳就不说了,直接在代码段下断,然后单步跟踪,很容易找到OEP
找到OEP后,LoadPE转储,ImportRec修复,找到修复无效指针直接剪贴,常规流程!但是,剪贴以后傻逼了,直接成下面这样了
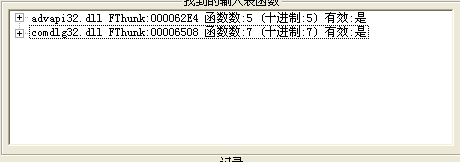
一个程序只导入了12个函数,可能吗?我只能说,可能性不大
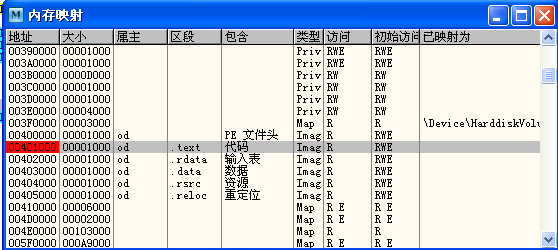
再看看内存镜像里面的IAT,万一ImportRec把IAT的偏移或者大小计算错了呢?这种情况经常发生!
查看内存镜像,如下图
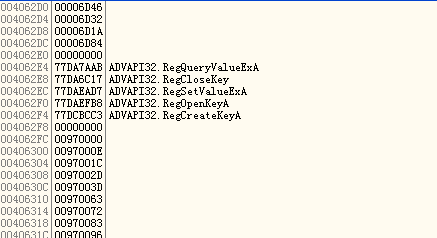
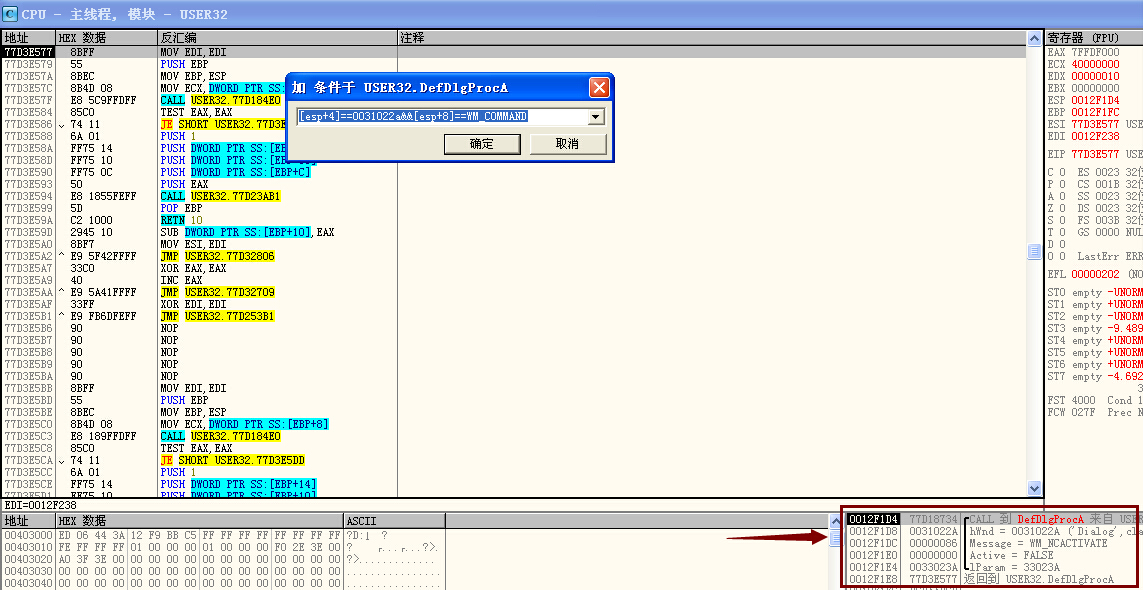
看来ImportRec没有出错,另外,可以看到,IAT里面有很多非DLL导出函数指针,这个应该就是壳修改以后的函数指针了,随便找一个位置(最好不要找第一个,这样可以有个参考),设置内存写入断点,看它是怎么写的.点了几次以后,内存镜像和中断位置如下

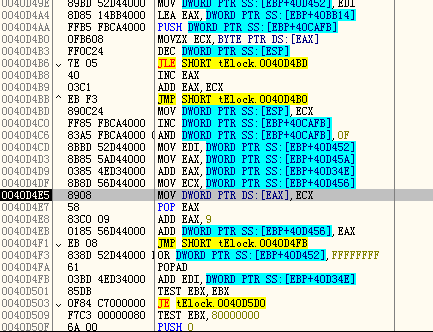
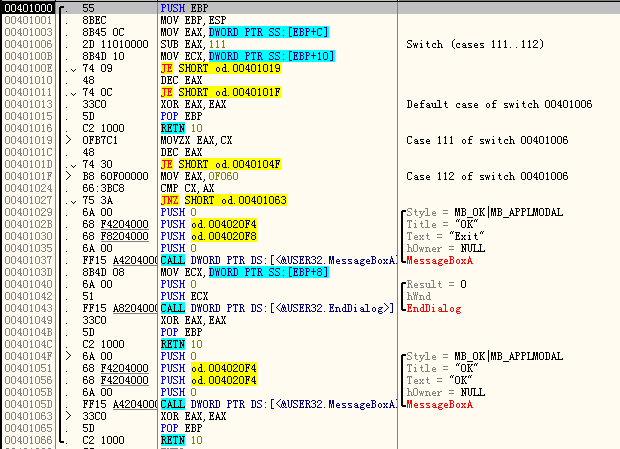
看来ECX存储的是函数指针,而上面又有MOV ECX,DWORD PTR SS:[EBP+40D456],所以直接找DWORD PTR SS:[EBP+40D456].
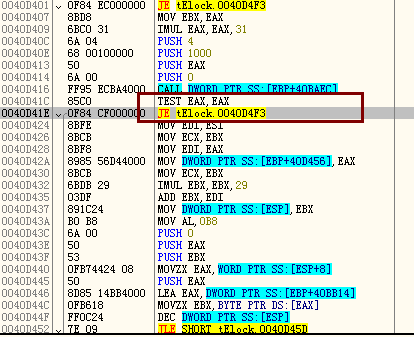
这里,记住这个位置,重新开始,在40d400下断.发现这里如果把JE改成JMP的话可以跳过刚才的代码,试下.
重新来到OEP,现在在看看IAT
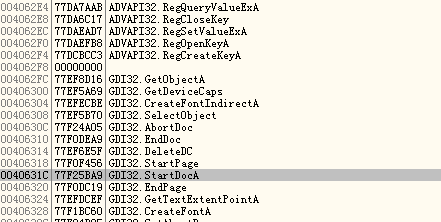
妥妥的!
PS:这种方法有时候会遇到壳自校验的问题,也就是说外壳发现你修改了代码,直接退出,这时,我们已经知道了IAT,直接用ImportRec修复之前保存好的转储文件就行了,其中,OEP填写真正的OEP.